IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019
Speech2Face: Learning the Face Behind a Voice
Supplementary Material
In this supplementary, we show the input audio results that cannot be included in the main paper as well as large number of additional qualitative results. The input audio can be played in the browser (tested on Chrome version >= 70.0 and HTML5 recommended).
** Headphones recommended **
 |
Figure 1: Teaser |
 |
Figure 3: Qualitative results on the AVSpeech Additional 500 randomly-sampled results on AVSpeech can be found HERE |
 |
Figure 4: Facial attribute evaluation |
 |
|
 |
Figure 6: The effect of input audio duration |
 |
Additional 100 randomly-sampled S2F-based retrieval results can be found HERE |
| Figure 8: Comparisons to a pixel loss | |
 |
Figure 10: Temporal and cross-video consistency |
 |
Figure 11: The effect of language |
 |
Figure 12: Failure cases |
 |
|
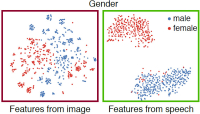 |
Figure 14: Visualizing the feature space |
Figure 1: Teaser
| True face (for reference) |
Face reconstructed from speech |
True face (for reference) |
Face reconstructed from speech |
||
 |
 |
 |
 |
||
| Input speech |
|||||
 |
 |
 |
 |
||
| Input speech |
|||||
 |
 |
 |
 |
||
| Input speech |
Teaser results on the VoxCeleb dataset. Several results of our method are shown. The true faces are shown just for reference; our model takes only an audio waveform as input. Note that our goal is not to reconstruct an accurate image of the person, but rather to recover characteristic physical features that are correlated with the input speech.
Figure 3: Qualitative results on the AVSpeech
| Original image (reference frame) |
Reconstruction from image |
Reconstruction from audio |
Original image (reference frame) |
Reconstruction from image |
Reconstruction from audio |
||
 |
 |
 |
 |
 |
 |
||
| Input speech |
|||||||
 |
 |
 |
 |
 |
 |
||
| Input speech |
|||||||
 |
 |
 |
 |
 |
 |
||
| Input speech |
|||||||
 |
 |
 |
 |
 |
 |
||
| Input speech |
|||||||
 |
 |
 |
 |
 |
 |
||
| Input speech |
|||||||
 |
 |
 |
 |
 |
 |
||
| Input speech |
|||||||
 |
 |
 |
 |
 |
 |
||
| Input speech |
|||||||
 |
 |
 |
 |
 |
 |
||
| Input speech |
Qualitative results on the AVSpeech test set. For every example (triplet of images) we show: (left) the original image, i.e., a representative frame from the video cropped around the speaker’s face; (middle) the frontalized, lighting-normalized face decoder reconstruction from the VGG-Face feature extracted from the original image; (right) our Speech2Face reconstruction, computed by decoding the predicted VGG-Face feature from the audio. In this figure, we highlight successful results of our method. Some failure cases are shown in Fig. 12.
See additional 500 randomly-sampled results on AVSpeech here.
Figure 4: Facial attribute evaluation
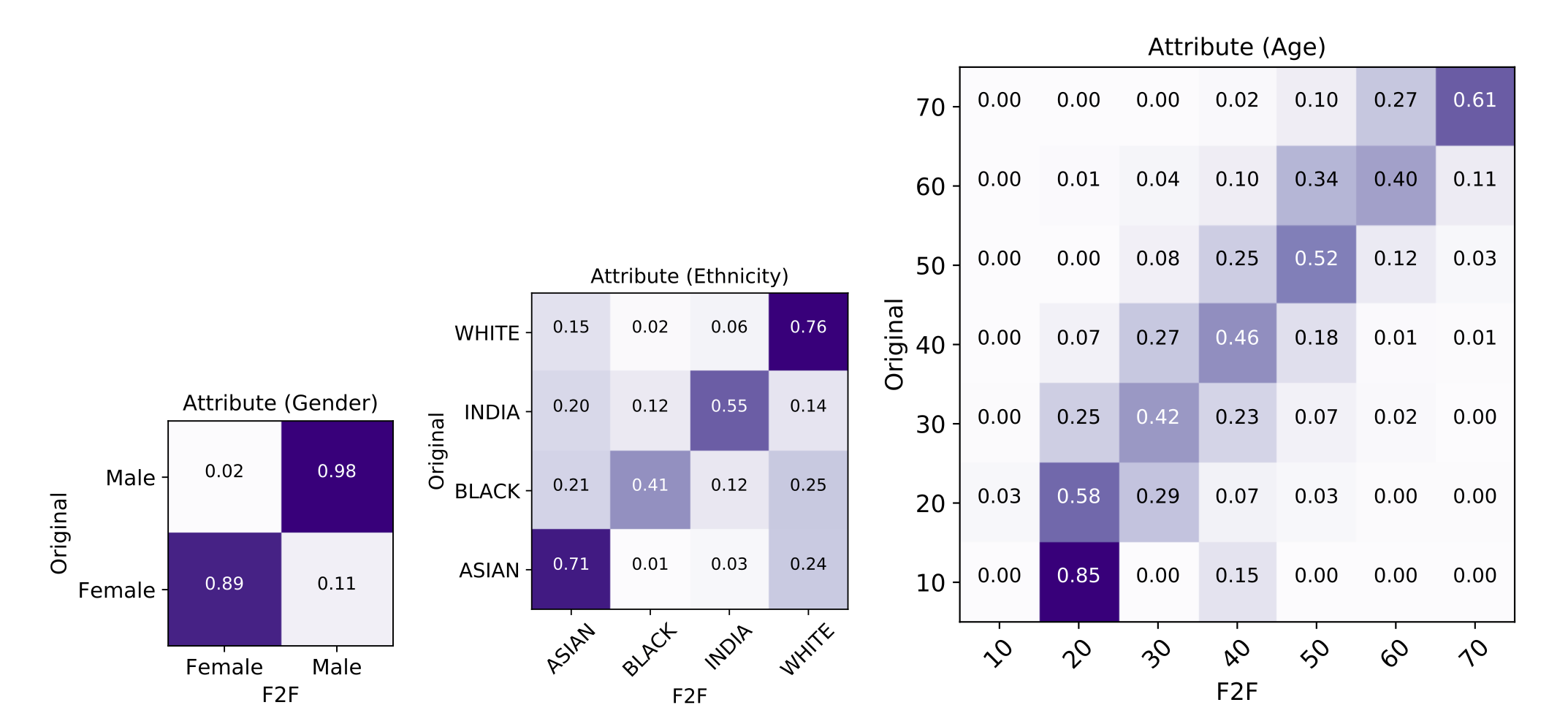
Attribute confusion matrix between original face image and face reconstruction from face feature. In the main paper, we show the facial attribute confusion matrices comparing the classification results on our Speech2Face image reconstructions and those obtained from the original images for gender, age, and ethnicity. Due to the domain gap between the original image and reconstructed faces, the usage of the existing classifier (Face++) may introduce some bias in the result. In this supplementary material, we show the confusion matrices comparing the classification results on face reconstructions from the original images and those obtained from the original images for reference to see the performance deviation sourced by the face decoder module. Please compare with Figure 4 in the main paper. The performance along diagonal entries can be considered as a pseudo upper bound of the performance of the confusion matrices in Figure 4. The confusion matrices are row-wise normalized, and strong diagonal tendency indicates better performance. We evaluate the attribute over the AVSpeech test set, which is consistent with Figure 4.
Figure 5: Craniofacial feature
|
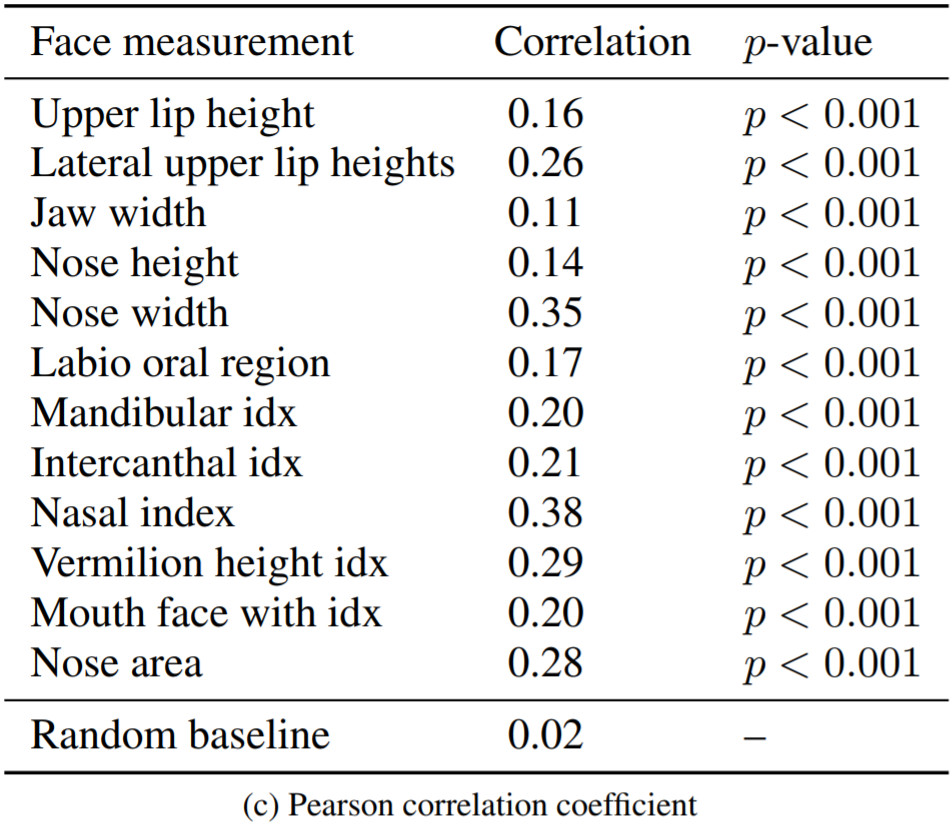 |
Craniofacial features. We measure the correlation between craniofacial features extracted from (a) face decoder reconstructions from the original image (F2F), and (b) features extracted from our corresponding Speech2Face reconstructions (S2F); the features are computed from detected facial landmarks, as described in [30]. The table reports Pearson correlation coefficient and statistical significance computed over 1,000 test images for each feature. Random baseline is computed for “Nasal index” by comparing random pairs of F2F reconstruction (a) and S2F reconstruction (b).
Figure 6: The effect of input audio duration
 |
 |
 |
 |
 |
 |
|
| 3 seconds |  |
 |
 |
 |
 |
 |
| 6 seconds |  |
 |
 |
 |
 |
 |
The effect of input audio duration. We compare our face reconstructions when using 3-second (middle row) and 6- second (bottom row) input voice segments at test time (in both cases we use the same model, trained on 6-second segments). The top row shows representative frames from the videos for reference. With longer speech duration the reconstructed faces capture the facial attributes better.
Figure 7: S2F-based retrieval
 |
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
|
S2F => Face retrieval examples. We query a database of 5,000 face images by comparing our Speech2Face prediction of input audio to all VGG-Face face features in the database (computed directly from the original faces). For each query, we show the top-5 retrieved samples. The last row is an example where the true face was not among the top results, but still shows visually close results to the query. In this figure, we highlight successful results of our method, and mark ground-truth matches by red color.
See additional 100 randomly-sampled S2F-based retrieval results here.
Figure 8: Comparisons to a pixel loss
Comparisons to a pixel loss. The results obtained with an L1 loss on the output image and our full loss (Eq. 1) are shown after 300k and 500k training iterations (indicating convergence).
Figure 10: Temporal and cross-video consistency
 |
 |
 |
 |
|
 |
 |
 |
 |
|
| (a) | (b) | |||
Temporal and cross-video consistency. Face reconstruction from different speech segments of the same person taken from different parts within (a) the same or from (b) a different video.
Figure 11: The effect of language
 |
 |
 |
 |
|
| (a) An Asian male speaking in English (left) & Chinese (right) | (b) An Asian girl speaking in English | |||
The effect of language. We notice mixed performance in terms of the ability of the model to handle languages and accents. (a) A sample case of language-dependent face reconstructions. (b) A sample case that successfully factors out the language.
Figure 12: Failure cases
 |
 |
 |
 |
|
| (a) Gender mismatch | (c) Age mismatch (old to young) | |||
 |
 |
 |
 |
|
| (b) Ethnicity mismatch | (d) Age mismatch (young to old) | |||
Example failure cases. (a) High-pitch male voice, e.g., of kids, may lead to a face image with female features. (b) Spoken language does not match ethnicity. (c-d) Age mismatches.
Figure 13: Speech-to-cartoon
|
Original image (reference frame) |
Reconstruction from audio |
Cartoon obtained from Gboard |
|

|

|

|
|
| Input speech |
|||

|

|

|
|
| Input speech |
|||

|

|

|
|
| Input speech |
|||

|

|

|
|
| Input speech |
|||

|

|

|
|
| Input speech |
|||
| (a) | (b) | (c) |
Speech-to-cartoon. Our reconstructed faces from audio (b) can be re-rendered as cartoons (c) using existing tools, such as the personalized emoji app available in Gboard, the keyboard app in Android phones. (a) The true images of the person are shown for reference.
Figure 14: Visualizing the feature space
In the main paper we show the t-SNE embeddings for the features of VoxCeleb samples. Here we show the t-SNE of AVSpeech samples.
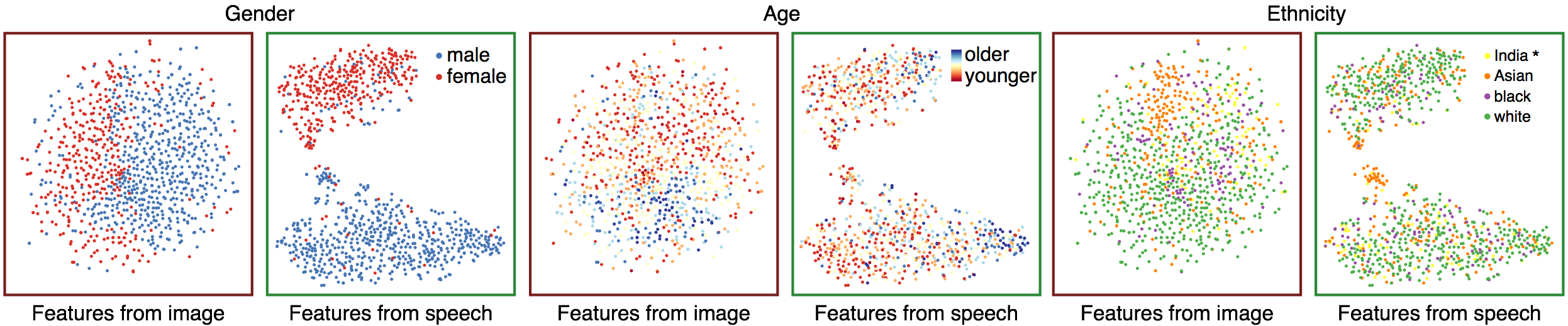
Visualizing the features space (AVSpeech). t-SNE visualizations of the AVSpeech samples for the face features obtained from the original images by feeding them into VGG-Face (red boxes), and for the features predicted by our voice encoder (green boxes). We use the same computed projections for each feature type, but in each plot color-code the data points using a different attribute (from left to right: gender, age, and ethnicity). We use the AVSpeech dataset and the attribute annotations obtained using the gender, age, and ethnicity classifiers available from the Face++ service (not used for training). Notice for example how gender is the major distinctive feature in our learned feature space, dividing the space into two separated clusters, as for the samples taken from the VoxCeleb dataset shown in Fig. 11 of the main paper. The face features (red boxes) show local clusters to a lesser degree than those of the VoxCeleb dataset, since the AVSpeech dataset includes a larger number of identities. *These labels are as obtained from the Face++ ethnicity classifier.